|
14 | 14 |
|
15 | 15 | ### 1. 存储结构 |
16 | 16 |
|
17 | | -> 下图存在两个笔误 : Segmeng -> Segment ; HashEntity -> HashEntry |
| 17 | + |
18 | 18 |
|
19 | | - |
20 | | - |
21 | | -Java 7 中 `ConcurrentHashMap` 的存储结构如上图,`ConcurrnetHashMap` 由很多个 `Segment` 组合,而每一个 `Segment` 是一个类似于 HashMap 的结构,所以每一个 `HashMap` 的内部可以进行扩容。但是 `Segment` 的个数一旦**初始化就不能改变**,默认 `Segment` 的个数是 16 个,你也可以认为 `ConcurrentHashMap` 默认支持最多 16 个线程并发。 |
| 19 | +Java 7 中 `ConcurrentHashMap` 的存储结构如上图,`ConcurrnetHashMap` 由很多个 `Segment` 组合,而每一个 `Segment` 是一个类似于 `HashMap` 的结构,所以每一个 `HashMap` 的内部可以进行扩容。但是 `Segment` 的个数一旦**初始化就不能改变**,默认 `Segment` 的个数是 16 个,你也可以认为 `ConcurrentHashMap` 默认支持最多 16 个线程并发。 |
22 | 20 |
|
23 | 21 | ### 2. 初始化 |
24 | 22 |
|
25 | | -通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。 |
| 23 | +通过 `ConcurrentHashMap` 的无参构造探寻 `ConcurrentHashMap` 的初始化流程。 |
26 | 24 |
|
27 | 25 | ```java |
28 | 26 | /** |
@@ -101,11 +99,11 @@ public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLe |
101 | 99 | 总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑。 |
102 | 100 |
|
103 | 101 | 1. 必要参数校验。 |
104 | | -2. 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无参构造**默认值是 16.** |
105 | | -3. 寻找并发级别 concurrencyLevel 之上最近的 **2 的幂次方**值,作为初始化容量大小,**默认是 16**。 |
106 | | -4. 记录 segmentShift 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。**默认是 32 - sshift = 28**. |
107 | | -5. 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15. |
108 | | -6. **初始化 segments[0]**,**默认大小为 2**,**负载因子 0.75**,**扩容阀值是 2*0.75=1.5**,插入第二个值时才会进行扩容。 |
| 102 | +2. 校验并发级别 `concurrencyLevel` 大小,如果大于最大值,重置为最大值。无参构造**默认值是 16.** |
| 103 | +3. 寻找并发级别 `concurrencyLevel` 之上最近的 **2 的幂次方**值,作为初始化容量大小,**默认是 16**。 |
| 104 | +4. 记录 `segmentShift` 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。**默认是 32 - sshift = 28**. |
| 105 | +5. 记录 `segmentMask`,默认是 ssize - 1 = 16 -1 = 15. |
| 106 | +6. **初始化 `segments[0]`**,**默认大小为 2**,**负载因子 0.75**,**扩容阀值是 2*0.75=1.5**,插入第二个值时才会进行扩容。 |
109 | 107 |
|
110 | 108 | ### 3. put |
111 | 109 |
|
@@ -179,23 +177,23 @@ private Segment<K,V> ensureSegment(int k) { |
179 | 177 | } |
180 | 178 | ``` |
181 | 179 |
|
182 | | -上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。 |
| 180 | +上面的源码分析了 `ConcurrentHashMap` 在 put 一个数据时的处理流程,下面梳理下具体流程。 |
183 | 181 |
|
184 | | -1. 计算要 put 的 key 的位置,获取指定位置的 Segment。 |
| 182 | +1. 计算要 put 的 key 的位置,获取指定位置的 `Segment`。 |
185 | 183 |
|
186 | | -2. 如果指定位置的 Segment 为空,则初始化这个 Segment. |
| 184 | +2. 如果指定位置的 `Segment` 为空,则初始化这个 `Segment`. |
187 | 185 |
|
188 | 186 | **初始化 Segment 流程:** |
189 | 187 |
|
190 | | - 1. 检查计算得到的位置的 Segment 是否为null. |
191 | | - 2. 为 null 继续初始化,使用 Segment[0] 的容量和负载因子创建一个 HashEntry 数组。 |
192 | | - 3. 再次检查计算得到的指定位置的 Segment 是否为null. |
193 | | - 4. 使用创建的 HashEntry 数组初始化这个 Segment. |
194 | | - 5. 自旋判断计算得到的指定位置的 Segment 是否为null,使用 CAS 在这个位置赋值为 Segment. |
| 188 | + 1. 检查计算得到的位置的 `Segment` 是否为null. |
| 189 | + 2. 为 null 继续初始化,使用 `Segment[0]` 的容量和负载因子创建一个 `HashEntry` 数组。 |
| 190 | + 3. 再次检查计算得到的指定位置的 `Segment` 是否为null. |
| 191 | + 4. 使用创建的 `HashEntry` 数组初始化这个 Segment. |
| 192 | + 5. 自旋判断计算得到的指定位置的 `Segment` 是否为null,使用 CAS 在这个位置赋值为 `Segment`. |
195 | 193 |
|
196 | | -3. Segment.put 插入 key,value 值。 |
| 194 | +3. `Segment.put` 插入 key,value 值。 |
197 | 195 |
|
198 | | -上面探究了获取 Segment 段和初始化 Segment 段的操作。最后一行的 Segment 的 put 方法还没有查看,继续分析。 |
| 196 | +上面探究了获取 `Segment` 段和初始化 `Segment` 段的操作。最后一行的 `Segment` 的 put 方法还没有查看,继续分析。 |
199 | 197 |
|
200 | 198 | ```java |
201 | 199 | final V put(K key, int hash, V value, boolean onlyIfAbsent) { |
@@ -249,29 +247,29 @@ final V put(K key, int hash, V value, boolean onlyIfAbsent) { |
249 | 247 | } |
250 | 248 | ``` |
251 | 249 |
|
252 | | -由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。 |
| 250 | +由于 `Segment` 继承了 `ReentrantLock`,所以 `Segment` 内部可以很方便的获取锁,put 流程就用到了这个功能。 |
253 | 251 |
|
254 | | -1. tryLock() 获取锁,获取不到使用 **`scanAndLockForPut`** 方法继续获取。 |
| 252 | +1. `tryLock()` 获取锁,获取不到使用 **`scanAndLockForPut`** 方法继续获取。 |
255 | 253 |
|
256 | | -2. 计算 put 的数据要放入的 index 位置,然后获取这个位置上的 HashEntry 。 |
| 254 | +2. 计算 put 的数据要放入的 index 位置,然后获取这个位置上的 `HashEntry` 。 |
257 | 255 |
|
258 | | -3. 遍历 put 新元素,为什么要遍历?因为这里获取的 HashEntry 可能是一个空元素,也可能是链表已存在,所以要区别对待。 |
| 256 | +3. 遍历 put 新元素,为什么要遍历?因为这里获取的 `HashEntry` 可能是一个空元素,也可能是链表已存在,所以要区别对待。 |
259 | 257 |
|
260 | | - 如果这个位置上的 **HashEntry 不存在**: |
| 258 | + 如果这个位置上的 **`HashEntry` 不存在**: |
261 | 259 |
|
262 | 260 | 1. 如果当前容量大于扩容阀值,小于最大容量,**进行扩容**。 |
263 | 261 | 2. 直接头插法插入。 |
264 | 262 |
|
265 | | - 如果这个位置上的 **HashEntry 存在**: |
| 263 | + 如果这个位置上的 **`HashEntry` 存在**: |
266 | 264 |
|
267 | | - 1. 判断链表当前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值 |
| 265 | + 1. 判断链表当前元素 key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值 |
268 | 266 | 2. 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。 |
269 | 267 | 1. 如果当前容量大于扩容阀值,小于最大容量,**进行扩容**。 |
270 | 268 | 2. 直接链表头插法插入。 |
271 | 269 |
|
272 | 270 | 4. 如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null. |
273 | 271 |
|
274 | | -这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 `tryLock()` 获取锁。当自旋次数大于指定次数时,使用 `lock()` 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。 |
| 272 | +这里面的第一步中的 `scanAndLockForPut` 操作这里没有介绍,这个方法做的操作就是不断的自旋 `tryLock()` 获取锁。当自旋次数大于指定次数时,使用 `lock()` 阻塞获取锁。在自旋时顺表获取下 hash 位置的 `HashEntry`。 |
275 | 273 |
|
276 | 274 | ```java |
277 | 275 | private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { |
@@ -311,7 +309,7 @@ private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { |
311 | 309 |
|
312 | 310 | ### 4. 扩容 rehash |
313 | 311 |
|
314 | | -ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表**头插法**插入到指定位置。 |
| 312 | +`ConcurrentHashMap` 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 `index+ oldSize`,参数里的 node 会在扩容之后使用链表**头插法**插入到指定位置。 |
315 | 313 |
|
316 | 314 | ```java |
317 | 315 | private void rehash(HashEntry<K,V> node) { |
@@ -406,7 +404,7 @@ public V get(Object key) { |
406 | 404 |
|
407 | 405 | ### 1. 存储结构 |
408 | 406 |
|
409 | | - |
| 407 | +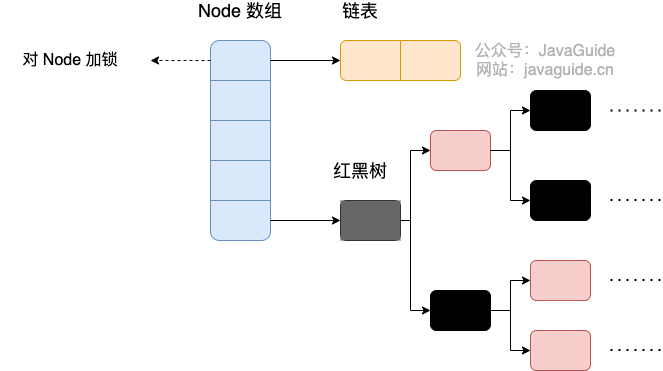 |
410 | 408 |
|
411 | 409 | 可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。当冲突链表达到一定长度时,链表会转换成红黑树。 |
412 | 410 |
|
@@ -442,7 +440,7 @@ private final Node<K,V>[] initTable() { |
442 | 440 | } |
443 | 441 | ``` |
444 | 442 |
|
445 | | -从源码中可以发现 ConcurrentHashMap 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` ,它的值决定着当前的初始化状态。 |
| 443 | +从源码中可以发现 `ConcurrentHashMap` 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` ,它的值决定着当前的初始化状态。 |
446 | 444 |
|
447 | 445 | 1. -1 说明正在初始化 |
448 | 446 | 2. -N 说明有N-1个线程正在进行扩容 |
@@ -541,7 +539,7 @@ final V putVal(K key, V value, boolean onlyIfAbsent) { |
541 | 539 |
|
542 | 540 | 5. 如果都不满足,则利用 synchronized 锁写入数据。 |
543 | 541 |
|
544 | | -6. 如果数量大于 `TREEIFY_THRESHOLD` 则要执行树化方法,在treeifyBin中会首先判断当前数组长度≥64时才会将链表转换为红黑树。 |
| 542 | +6. 如果数量大于 `TREEIFY_THRESHOLD` 则要执行树化方法,在 `treeifyBin` 中会首先判断当前数组长度≥64时才会将链表转换为红黑树。 |
545 | 543 |
|
546 | 544 | ### 4. get |
547 | 545 |
|
@@ -583,12 +581,12 @@ public V get(Object key) { |
583 | 581 |
|
584 | 582 | 总结: |
585 | 583 |
|
586 | | -总的来说 ConcurrentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的, |
| 584 | +总的来说 `ConcurrentHashMap` 在 Java8 中相对于 Java7 来说变化还是挺大的, |
587 | 585 |
|
588 | 586 | ## 3. 总结 |
589 | 587 |
|
590 | | -Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。 |
| 588 | +Java7 中 `ConcurrentHashMap` 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 `Segment` 都是一个类似 `HashMap` 数组的结构,它可以扩容,它的冲突会转化为链表。但是 `Segment` 的个数一但初始化就不能改变。 |
591 | 589 |
|
592 | | -Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 **Segment 数组 + HashEntry 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。 |
| 590 | +Java8 中的 `ConcurrentHashMap` 使用的 `Synchronized` 锁加 CAS 的机制。结构也由 Java7 中的 **`Segment` 数组 + `HashEntry` 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。 |
593 | 591 |
|
594 | | -有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的**锁升级**。 |
| 592 | +有些同学可能对 `Synchronized` 的性能存在疑问,其实 `Synchronized` 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 `Synchronized` 的**锁升级**。 |
0 commit comments